#ai-inference
29 episodes

#2467: The Time Tax on API Access
How OpenAI and Anthropic structure API tiers, rate limits, and why your billing history matters more than you think.

#2464: Batch APIs: The 50% Discount You're Probably Misusing
Batch inference APIs offer 50% off — but only for the right workloads. Here's when they actually make sense.

#2456: Choosing Between AI Cloud Providers
A practical guide to choosing between Modal, RunPod, Nebius, and Baseten for AI workloads.
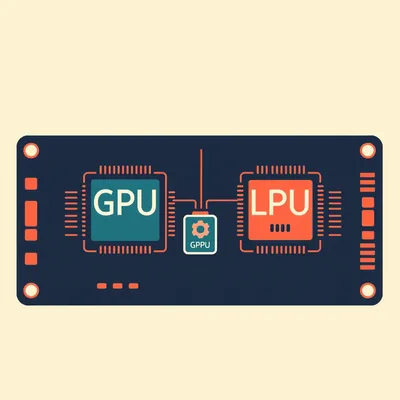
#2431: The 3 Markets in an AI Trench Coat
GPUs, LPUs, and ASICs: why the best hardware for AI depends entirely on what you're trying to do.

#2254: How to Test an AI Pipeline Change
When you tweak one part of a complex AI agent system, how do you know if it actually improved anything? The answer lies in engineering checkpoints.

#2249: Building Custom Benchmarks for Agentic Systems
Public benchmarks fail for agentic systems. Learn how to build evaluation frameworks that actually predict production behavior.

#2243: What Enterprise AI Pricing Actually Negotiates
Enterprise customers rarely get the deep discounts they expect from AI APIs. What they actually negotiate for—and why the ramp-up requirement exist...

#2214: The Three Failure Modes of AI News Systems
When a conflict changes hourly, AI systems built for yesterday's information fail. Here's how to architect pipelines that actually keep up.

#2184: The Economics of Running AI Agents
Production AI agents can cost $500K/month before optimization. Learn model routing, prompt caching, and token budgeting to cut costs 40-85% without...
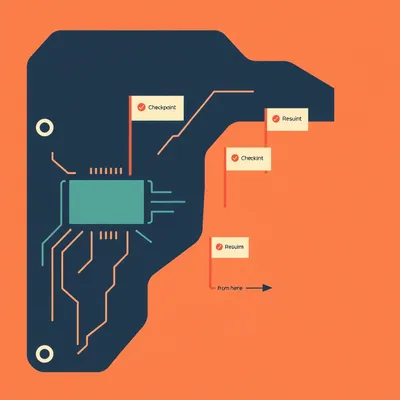
#2179: Building Cost-Resilient AI Agents
Failed API calls in agent loops aren't just technical problems—they're direct budget drains. Here's how checkpointing, retry strategies, and cachin...

#2160: Claude's Latency Profile and SLA Guarantees
Claude is measurably slower than competitors—and Anthropic's SLA promises are even thinner than the latency numbers suggest. What enterprises actua...

#2123: Human Reaction Time vs. AI Latency
We obsess over shaving milliseconds off AI response times, but human biology has a hard limit. Here’s why your brain can’t keep up.
#2115: Why AI Answers Differ Even When You Ask Twice
You ask an AI the same question twice and get two different answers. It’s not a bug—it’s physics.

#2065: Why Run One AI When You Can Run Two?
Speculative decoding makes LLMs 2-3x faster with zero quality loss by using a small draft model to guess tokens that a large model verifies in para...

#2060: The Tokenizer's Hidden Tax on Non-English Text
Why does a simple greeting in Mandarin cost more to process than in English? It's the tokenizer's hidden inefficiency.

#2040: The Rebellion Against Big Tech's AI Lock-In
Why run LLMs locally? We break down Ollama, llama.cpp, vLLM, and llamafile—and when to use each.

#2022: When AI Becomes Your IT Department
We dug into a repo of 47 real-world projects showing how OpenClaw powers everything from self-healing servers to overnight app builders.

#1831: The 79% AI Coder: Reasoning vs. Memorization
AI models now score 79% on coding benchmarks, but a 40-point drop on harder tests reveals the truth.

#1782: Jenkins, GitHub, or Tekton? Picking Your 2025 CI/CD Engine
Jenkins is still the COBOL of DevOps, but the "one size fits all" model is dead. Here’s how to pick your pipeline.

#1756: The Ferrari in the Mud: Prestige Flops
We count down the five worst serious movies of the last five years, starting with a sci-fi disaster that wasted $80 million.

#1620: Why VRAM Is the Wrong Way to Measure Your AI PC
Forget VRAM—bandwidth is the new king. Discover why your local AI feels slow and how to build a true "agent computer" for professional coding.

#1556: The War Against Latency: Engineering Real-Time AI
From KV cache monsters to sub-100ms response times, explore the hardware and software innovations making real-time AI a reality.

#1479: The Speed of Thought: Inside the New Era of Inference
The war for model size is over. Explore the engineering breakthroughs making massive AI models faster than human thought.

#1084: Why AI Models Can’t Read and Your Bill Is Rising
Why does the same prompt cost more on different models? Discover the "invisible wall" of tokenization and how it shapes AI perception.