Page 8 of 218

#4283: The Nightclub Confrontation That Exposed a Toxic Pipeline
How looksmaxxing forums, livestreaming platforms, and algorithmic amplification converge to radicalize teenagers.

#4282: Beyond the Tourist Trail: Finding Cities Worth the Trip
How to find well-connected cities that aren't overrun with tourists — Bilbao, Gdańsk, Turin, and Plovdiv.

#4281: Why Déjà Vu Feels Like a Memory Glitch
The strange feeling of reliving a moment isn't a glitch—it's your brain's familiarity alarm going off by mistake.

#4280: Work Pants That Survive Real Abuse
Which workwear brands actually survive dryer abuse, heavy belts, and real job site wear?

#4279: The Senator Who Became Israel's Backchannel
How one senator built a unique role as Israel's most trusted American ally — and why his death leaves a gap no one can fill.

#4278: Designing a DIY Meal Replacement from First Principles
Powder beats bars for low-fat, shelf-stable meal replacements. Here's how to design your own from scratch.

#4277: Flowcharts vs Soup: Two Ways Brains Solve Problems
Why some brains finish A before B while others happily juggle ten things at once.

#4276: Text Expansion Across Devices: The Real Cross-Platform Guide
Espanso vs TextExpander vs Gboard — what actually works when you need snippets on Linux and Android?

#4275: From $15 AliExpress Belt to Full EDC System
How belt width changes everything about your carry system — and what to do about it.

#4274: Fixing Loop-Damaged Podcasts with AI and FFmpeg
Can an AI agent detect repeated audio, generate FFmpeg commands, and overwrite files in cloud storage without breaking RSS?

#4273: UPS vs Generator: Where's the Line Now?
Lithium batteries are making home UPSs bigger and cheaper. But when does a generator still win?

#4272: Why Are Light Switches Banished to Industrial Wastelands?
How a 1926 Supreme Court case about a "pig in the parlor" still determines where you can buy a pipe fitting.
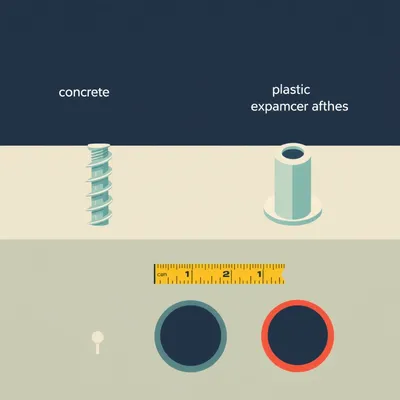
#4271: Concrete Screws vs Plastic Anchors: Best for Renters
Concrete screws hold 2-3x more weight than plastic anchors and leave smaller holes. Here's what Israeli renters need to know.

#4270: The Anchor Go Bag: A System for Hanging Anything
Stop googling anchor sizes. A decision tree for drywall, concrete, and everything in between.

#4269: Who Are the Haredim? Inside Israel's Fastest-Growing Community
How a temporary 1947 exemption for 400 yeshiva students became a crisis for 66,000 — and what it means for Israel's future.

#4268: When AI Trains on AI: The Model Collapse Problem
What happens when AI trains only on AI-generated content? The answer is model collapse — and it's already happening.

#4267: The World's Most Dangerous Airline and Airspace
Yeti Airlines tops the fatal accident rate. But the real hazard may be the airspace it flies through.

#4266: How to Read a Freight Quote Without Getting Burned
Your $2,200 freight quote just turned into $3,800. Here’s how to spot the hidden fees before you pay.

#4265: Who Actually Handles AliExpress Customs?
What happens when a customs broker emails you about your AliExpress order? Here's how it really works.

#4264: EXW vs FOB: Real Costs and Hidden Fees for China Imports
Which incoterm saves you money? The answer depends on factory location, supplier capability, and hidden fees.