Speech & Audio
Voice AI, speech recognition, and audio processing
32 episodes

#3446: Where to Clip a Speaker for the Best Sound
Tiny placement changes dramatically alter sound. Learn the physics of where to clip your speaker for the best audio.

#3189: Drawing the Melody: SSML's Hidden Power
How SSML gives developers narrative control over AI voices — and why ElevenLabs became its center of gravity.

#3020: How Chatterbox Locks Your Voice Clone Across Thousands of Generations
Why most single-shot TTS models drift over time—and how Chatterbox's cached embedding approach solves it.

#2982: Why Your TTS Model Nails "Shabbat" but Not "Keren Hishtalmut
Why multilingual TTS models handle loanwords but fail at niche vocabulary — and what you can do about it.

#2914: Can AI Read the Room? TTS Prosody Explained
Can TTS models truly infer emotion from text, or just mimic patterns? We break down the science of prosody.

#2886: How Acoustic Cameras Catch Honking Drivers
Can an acoustic camera pinpoint one honk in a traffic jam? The tech is real, and fines are being issued.

#2781: When Voice AI Features Enable Fraud
Voice AI platforms now let you simulate background noise, hesitation, and natural conversation — and that's a problem.

#2754: Why Your Dictation Setup Might Be Wrong
Modern ASR is shockingly robust. The biggest predictor of accuracy? How well your audio matches its training data.
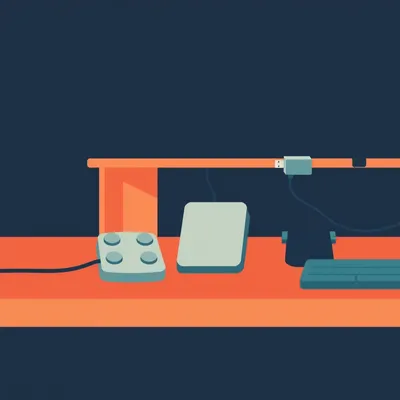
#2707: Foot Pedals vs USB Buttons: The Ergonomics of Dictation
Foot pedals, USB buttons, and under-desk macro pads for voice dictation — a deep dive into the hardware that makes AI dictation work.

#2618: Text Normalization's Hidden Complexity
How to handle acronyms in text-to-speech pipelines using BERT models, lexicons, and layered preprocessing.

#2602: Letting Non-Experts Direct Audio Tools Through Conversation
How to use AI for podcast mastering — and why agentic AI works better for small tasks than big promises.

#2591: Decoupling Script from Voice
How dynamic voice replacement could let listeners choose who narrates each host's lines.

#2590: The Uncanny Valley of Clean Speech
How transformer models distinguish "um" from meaningful speech — and why removing too much makes you sound like a robot.
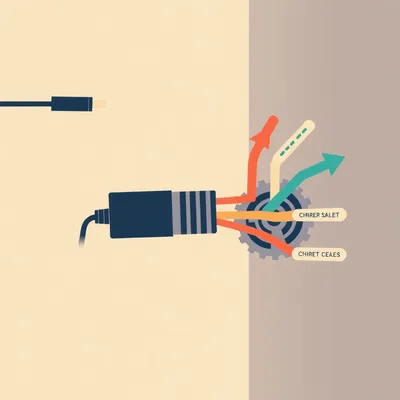
#2582: What Your Browser Does to Mic Audio Before It Reaches Your Server
getUserMedia returns audio, but not raw audio. Here's what browsers actually do to your mic feed before it hits your server.

#2563: How Audio Fingerprinting Actually Works
Spectrogram peaks, constellation maps, and hash matching — the elegant mechanics behind identifying any song in seconds.

#2543: Why Base64 Adds 33% Overhead (And Why You Still Need It)
Base64 isn’t compression — it’s a safe transport encoding. Here’s how it works with audio APIs and where its limits are.

#2512: How Speech-to-Speech Models Eliminate the Robot Voice
Why AI voice agents sound robotic, and how natively integrated speech-to-speech models fix it.

#2510: The Design That Makes Voice Agents Tolerable
Drive-thru accuracy, healthcare triage, and the design secret that makes people *want* to talk to a machine.
#2486: Why Noise Reduction Can Ruin Transcription Accuracy
Cleaning audio before transcription can increase errors by up to 46%. Here's the right approach for your voice app.

#2479: The Screaming Baby Stress Test
Choosing the right headset and control method for dictation when you're holding a baby who won't stop screaming.

#2443: How Podcast RSS Feeds Can Speak Every Language
One RSS feed, a transcript tag, and TTS voice cloning — the emerging standard for letting any podcast speak any language.

#2337: When Diarization Fails Silently
Discover how PyAnnote and other tools tackle the critical task of identifying "who spoke when" in audio—and why it’s harder than it sounds.

#2311: Danish AI: Bridging the Localization Gap
How does AI handle Danish? Explore the challenges and progress in making AI tools work for small-language populations.

#2288: The Invisible Gatekeeper of Voice Tech
How voice activity detection shapes every step of the voice tech pipeline, and why it’s harder than it seems.